Today’s The Register article by Agam Shaw, RISC-V takes steps to minimize fragmentation, discusses RISC-V International’s efforts to grapple with the RISC-V instruction set architecture’s growing pains as its diverse community strives to apply and optimize RISC-V to many different use cases.
There is a fundamental tension between development of new RISC-V optional standard extensions which must be non-proprietary, of broad interest and general utility, which may take years to reach consensus and ratification, and which consume a shared, limited resource (RISC-V encoding space and overall complexity), versus development of a custom extension, which may be the work of one party, in house, in one day, narrowly targeted, and/or proprietary. Both are valuable and necessary. However, RISC-V does not currently provide means to make these custom extensions, their hardware implementations, and their software libraries, reusable and interoperable, which does silo solutions and fragments the ecosystem.
Imagine you could combine the guaranteed correct composition of the optional standard instruction set extensions, and the agility of custom extensions. For several years, a small group of RISC-V FPGA soft processor developers and users have met informally, on and off, working towards this vision.
This first edition of the spec focuses on the prerequisite common HW-HW and HW-SW interfaces, formats, and metadata required to achieve robust automatic composition of custom extensions. Notably the spec includes a chapter on the Custom Function Unit Logic Interface, a HW-HW interface for composable custom function units that plug-and-play into different processors and systems. Beyond this spec, much work remains to define the software stack and software tooling above these interfaces, flesh out the Runtime, etc.
We just submitted a one page abstract for a poster which we hope may be presented and discussed at the upcoming 2022 Spring RISC-V Week in Paris. If the 50 page spec is daunting, this one page TLDR abstract attempts to provide a brief overview of some objectives and contributions of the work.
To get involved with this work, stay tuned, we will set up a public mailing list for discussions momentarily (and update this paragraph). Also please raise your spec concerns and suggestions in the Issues list. Thank you for your interest. Onwards!
Whenever we specify new a custom extension, implement it as a custom function unit, or target it as an accelerated library, let us do so using common, standardized interoperation interfaces so that it may “just work” with all RISC-V CPUs and the other standard and custom extensions.
Composable Custom Extensions and Custom Function Units for RISC-V (Poster Abstract submited for 2022 Spring RISC-V Week)
Jan Gray (Gray Research) , Tim Vogt (Lattice Semiconductor), Tim Callahan (Google), Charles Papon (SpinalHDL), Guy Lemieux (University of British Columbia), Maciej Kurc (Antmicro), Karol Gugala (Antmicro)
This poster introduces a draft specification for composable custom instruction extensions in RISC-V. The RISC-V custom instruction encoding space is unmanaged, leading to potential conflicts when combining different accelerators and their libraries into one system. This specification defines interop interfaces including a physical logic interface and CSRs that manage the composition of multiple, independently developed custom instruction extensions. Contributions include custom interface multiplexing and stateful but isolated state for multiple harts sharing multiple custom function units (CFUs).
Today, custom extensions don’t interoperate
SoCs may use app-specific hardware accelerators to improve performance and energy – particularly so with FPGA SoCs that offer plasticity and abundant spatial parallelism. The RISC-V ISA explicitly supports domain-specific custom extensions.
There are many RISC-V processors with custom instruction extensions, and now some vendor tooling. But the accelerated libraries that use these extensions and the cores that implement them are authored by different organizations, using different tools, and may not work together. Different custom extensions may conflict in use of opcodes, or their implementations may require different CPU cores, pipeline structures, logic interfaces, models of computation, means of discovery, context switching, or error reporting. Composition is difficult, impairing reuse of hardware and software, and fragmenting the RISC-V ecosystem.
Unleashing innovation in interoperable custom extensions
RISC-V International uses a community process to define a new standard extension to the RISC-V ISA. New extensions must be of broad interest and utility to merit allocation of precious RISC-V opcode space, CSR space, and generally to add to the enduring complexity of the platform. New extensions typically require years to reach consensus and ratification. Each coexists with all other extensions. Might any new custom extension also safely coexist (compose) with all extensions? Might there be a rich ecosystem of plug-and-play custom extensions? Yes!
Our proposed interop interfaces allow any party to rapidly define, develop, and use:
a custom interface (CI): a custom extension consisting of a set of custom function (CF) instructions,
a custom function unit (CFU): a composable hardware core that implements a custom interface,
an accelerated CI library that issues custom instructions,
a processor that can mix and match any CFUs (plural), and
tools to create and compose these elements into systems.
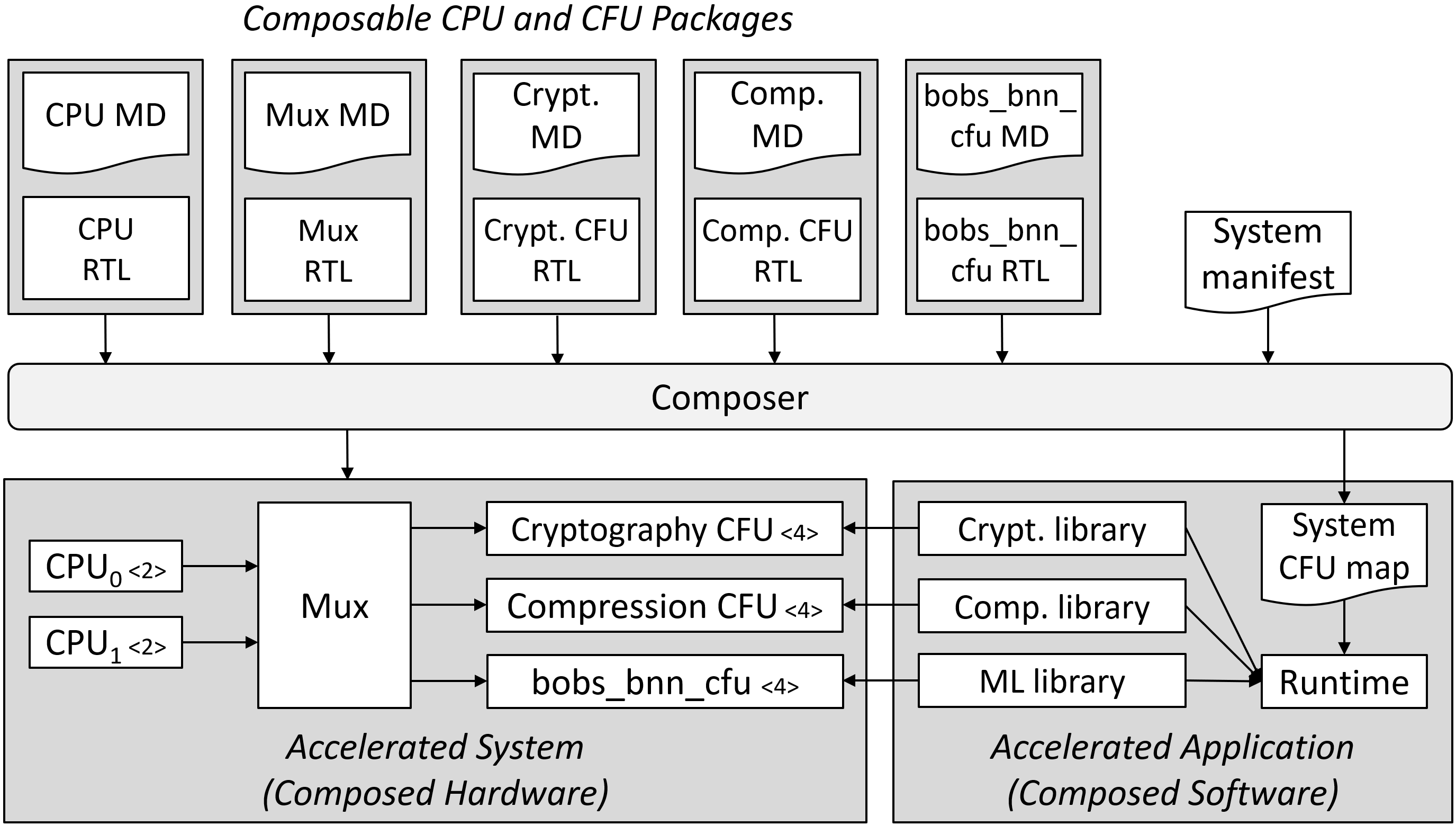
Composing packages of custom interfaces, CPU and CFU cores, and accelerated libraries, into systems
Custom interfaces, their CFUs and libraries, may be open or proprietary, even of narrow interest. Anyone can mint a new one. A new CPU core can use existing CFUs and libraries. A new interface, CFU, or library can be used by existing CPUs and systems. Many CFUs may implement a given custom interface, and many libraries may issue instructions of a custom interface.
Such composition requires routine integration of separately authored, separately versioned elements into stable systems that just work together, now, and over time, as elements evolve. To ensure composition does not change the behavior of any interface, interfaces’ state contexts are isolated: a CF instruction only accesses its source operands and its current state context.
Custom interface multiplexing
Custom interface multiplexing provides an inexhaustible, collision-free opcode space for custom instructions without any central opcode authority. Every new interface can use any or all of the custom-0/-1 opcode space. Each accelerated CI library, prior to issuing any custom instructions, calls a runtime to obtain that interface’s (CFU,state)selector value and write it to a new mcfu_selector CSR. This selects the hart’s current interface (and CFU core) and its current interface state context. Like the vector extension’s vsetvl instruction, an mcfu_selector write configures the behavior of custom instructions that follow.
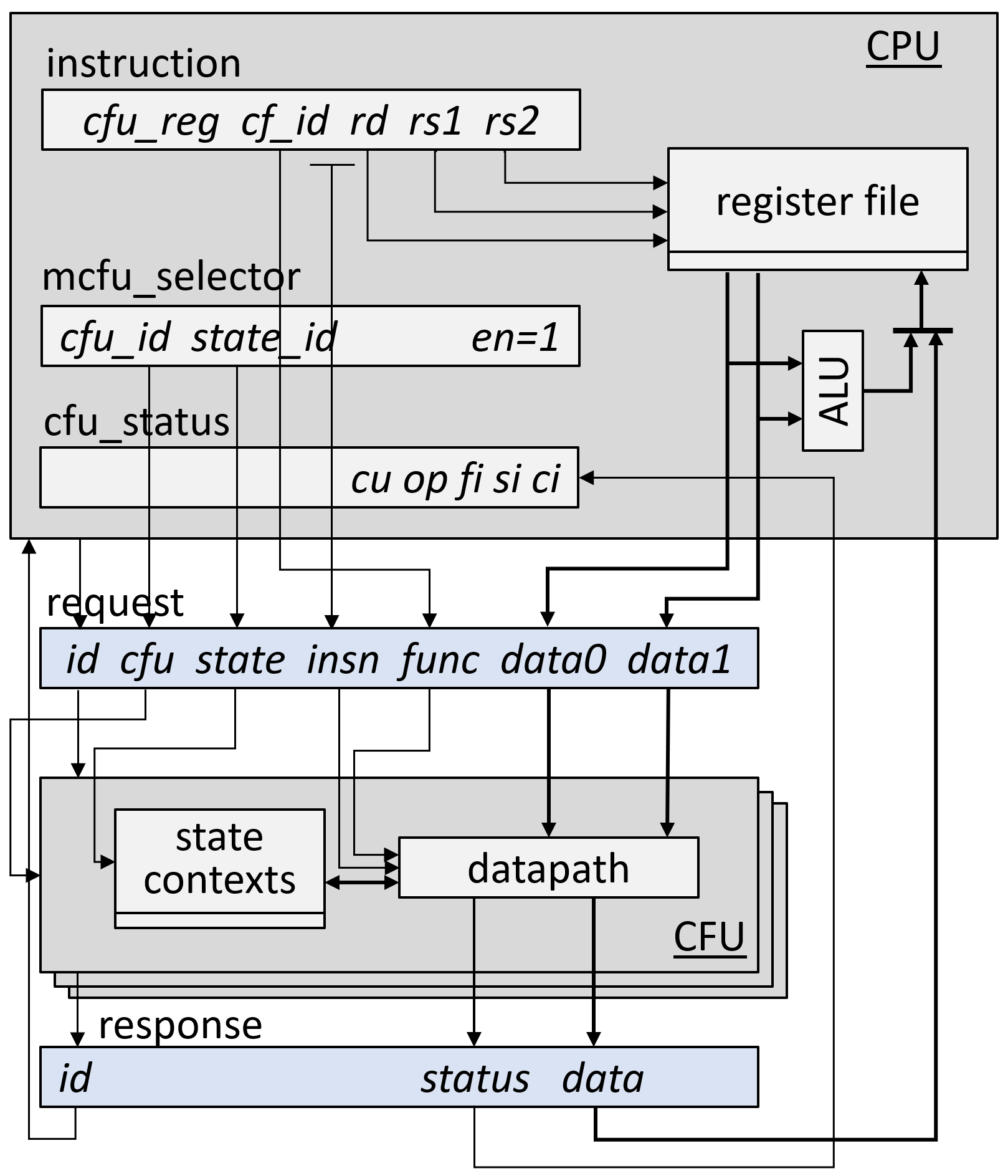
HW-SW interface: issuing a custom function instruction using custom interface multiplexing ⇒ CFU logic interface
Custom function unit logic interface (CFU-LI)
A CPU executes a CF instruction by sending a CFU request to a CFU, carrying context IDs and operands. The CFU processes the request, may update its state, and sends a CFU response, which updates a destination register and the cfu_status CSR.
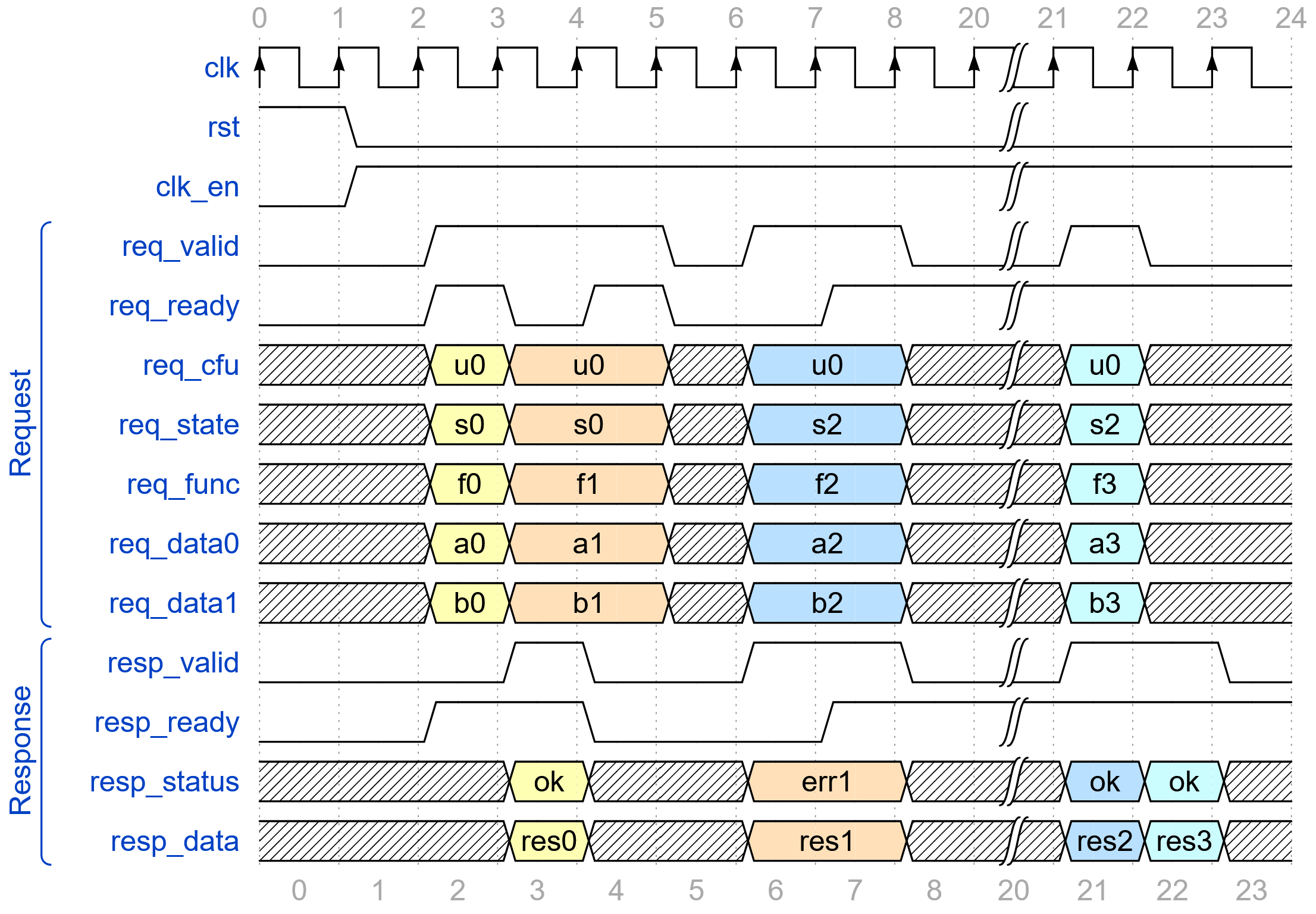
The CFU-LI defines standard signaling and metadata for combinational, fixed-latency, and variable-latency CFUs, so that CPU and CFU packages may be automatically composed.
Example variable-latency, flow controlled CFU-L2 transactions
A 1680-core, 26 MB GRVI Phalanx on VU9P on VCU118, with a 7×30×300b Hoplite NoC and 7×30 clusters of { 8 RISC-V cores + 128 KB }, running a message passing, bulk synchronous integer matrix multiplies demo, and
An 80-core GRVI Phalanx on 7Z020 on PYNQ-Z1, with a 4×4×300b Hoplite NoC and 10 clusters of { 8 RISC-V cores + 32 KB }, running an AXI4 DRAM/RDMA bridge test of 80×256B×2^28 reads. (Some of the 80 cores’ blue and white subwindows of the console are visible in the photo below.)
This just underscores that I need to invest in better demos.
Demos of GRVI Phalanx on PYNQ-Z1 (80 cores) and VCU118 (1680 cores) at the RISC-V table at Hot Chips 29
This event was a special occasion for me. I’ve attended Hot Chips conferences since the late 1980s. Then, as a software engineer fascinated by computer architecture and following USENET’s comp.arch gang, it was a thrill for me to head to Stanford and meet my heroes, microprocessor architects, and learn more about how their new parts worked, and I’d return with new insights that made me a better software engineer.
Back in the ’80s, only chip design teams had the EDA tools and fabs necessary to build microprocessors. But starting in the ’90s, larger and more capable FPGAs, with increasingly comprehensive tools and infrastructure, enabled anyone to develop FPGA CPUs and now parallel computers. FPGAs democratize access to high performance digital design, and yesterday to bring this full circle, I demonstrated a parallel computer system on a chip integrating the greatest number of 32-bit RISC processors ever. With this kind of work, and with the Microsoft Brainwave announcement, FPGA designers are emphatically not second class, second best to inflexible ASICs. Rather FPGA platforms are coequal and indeed are the vanguard of agile computer architecture.
The work-in-progress GRVI Phalanx massively parallel accelerator framework has been ported to the Xilinx Virtex UltraScale+ XCVU9P.
On Dec. 30, 2016, a design with 30 rows by 7 columns of clusters of 8 GRVI RISC-V cores + 128 KB CRAM (cluster RAM) + a 300-bit Hoplite NOC router — a total of 1680 cores and 26 MB of SRAM — booted up and tested successfully, running a message passing matrix multiply workload on all 1680 cores, in a XCVU9P-FLGA2104-2L-E-ES1 device in a Xilinx VCU118 evaluation kit.
This 1680 core GRVI Phalanx is the first operational kilocore RISC-V, the first kilocore 32b RISC in an FPGA, and the most 32b RISC cores on a chip in any technology.
1 core, 32 cores, 1680 cores — RISC-V scales up! A 1-core Si-Five HiFive-1, a 2x2x8=32-core GRVI Phalanx in a Digilent Arty / XC7A35T, and a 30x7x8=1680-core GRVI Phalanx in a Xilinx VCU118 / XCVU9P.
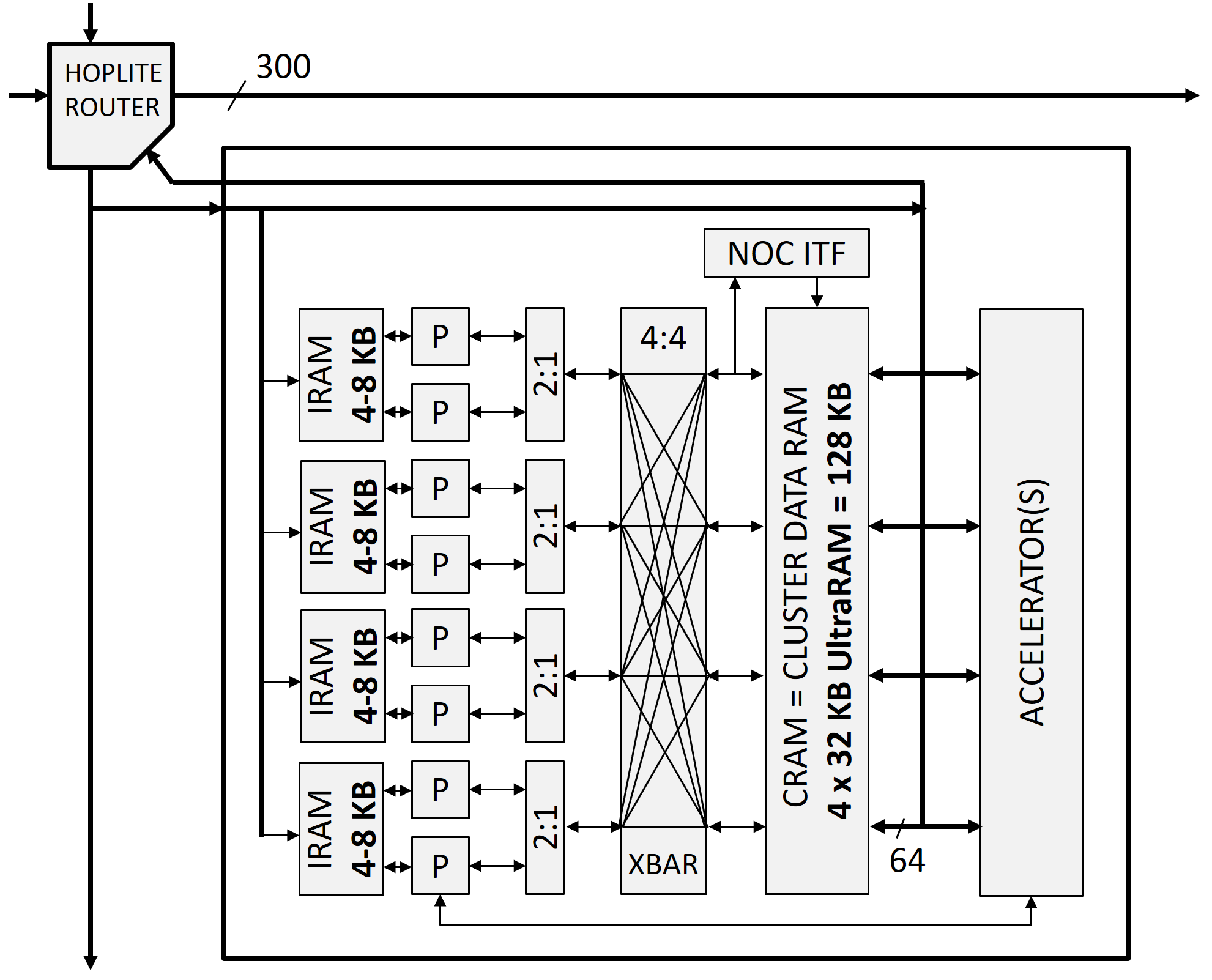
Here is the basic cluster tile architecture redesigned for UltraScale+ and its new 288 Kb UltraRAM jumbo-SRAM blocks. The present design includes 210 instances of this tile.
A GRVI cluster tile with 8 GRVI RISC-V cores, 128 KB multiported bank interleaved shared cluster RAM, optional accelerators (here, none), message passing NOC interface, and a 300-bit wide Hoplite NOC router.
An example 1680 GRVI system implemented in a Xilinx Virtex UltraScale+ VU9P. This GRVI Phalanx comprises NX=7 x NY=30 = 210 clusters, each cluster with 8 GRVI cores and a 8-ported 128 KB cluster shared memory. The clusters are interconnected on a Hoplite NOC, with the Hoplite routers configured with 290b data payloads (including 32b address and 256b data), achieving a bandwidth of about 70 Gb/s/link and a NOC bisection bandwidth of 900 Gb/s. Each cluster can send or receive 32 B per cycle into the NOC. The GRVI Phalanx architecture anticipates a variety of configurable accelerators coupled to the processors, the cluster shared RAM, or the NOC.
An extended abstract with additional detail on this work has been submitted to, and hopefully will be presented at, the OLAF’17 workshop at FPGA’17.
GRVI Phalanx was discussed in the short talk Software-First, Software Mostly: Fast Starting with Parallel Programming for Processor Array Overlays at the Arduino-like Fast-Start for FPGAs pre-conference workshop at FCCM 2016. [Slides]
Here are some of the changes made to the GRVI Phalanx design since it was first described at the 3rd RISC-V Workshop. This is now version 0.2.
GRVI
LB/LBU/LH/LHU/SB/SH: Load/store byte and halfword alignment functionality is now configured OFF in the GRVI PEs. The LdMux and StMux units have been factored out of GRVI and into the GRVI cluster, each set of muxes shared by a pair of cores.
MUL/MULH/MULHU/MULHSU: The multiply instructions from the RISC-V “M” extension are now enabled by default and are implemented in the GRVI cluster. Each pair of processors shares one DSP-based multiplier. This consumes 200 DSP48s in the 400 PE GRVI Phalanx for Kintex UltraScale 040, leaving 1720 DSP48s for use by accelerators.
SL*/SR*: By default, fast left and right shift instructions are also implemented in these DSP-based multipliers.
LR/SC: These atomic instructions from the RISC-V “A” extension are now enabled by default. Part of the implementation is in the GRVI core and part in the GRVI cluster memory arbiters. The implementation considerations were discussed on the RISC-V mailing lists here.
Phalanx
A Phalanx system may be configured to replace the cluster at (NX-1,NY-1) with a character mode VGA cluster with a 32 KB text frame buffer.
Hoplite multicast message routing is now enabled by default. An agent can sent a message to every cluster on a given row, given column, or to every cluster on the NOC. If desired, all IRAMs in all clusters in a Phalanx may be updated with a single burst of 1024 XY-multicast messages.
GRVI is an FPGA-efficient RISC-V RV32I soft processor core, hand technology mapped and floorplanned for best performance/area as a processing element (PE) in a parallel processor. GRVI implements a 2 or 3 stage single issue pipeline, typically consumes 320 6-LUTS in a Xilinx UltraScale FPGA, and currently runs at 300-375 MHz in a Kintex UltraScale (-2) in a standalone configuration with most favorable placement of local BRAMs.
Phalanx is massively parallel FPGA accelerator framework, designed to reduce the effort and cost of developing and maintaining FPGA accelerators. A Phalanx is a composition of many clusters of soft processors and accelerator cores with extreme bandwidth memory and I/O interfaces on a Hoplite NOC.
GRVI Phalanx was introduced today at the 3rd RISC-V Workshop at Redwood Shores, CA.
A work-in-progress 5x10x8 = 400 processor configuration in a KU040 in a Xilinx KCU105 and a 2x2x8 = 32 processor configuration in a Xilinx Artix-7 35T in an Digilent Arty were demonstrated in the demo/poster session.
For more information please visit the GRVI Phalanx page.