The work-in-progress GRVI Phalanx massively parallel accelerator framework has been ported to the Xilinx Virtex UltraScale+ XCVU9P.
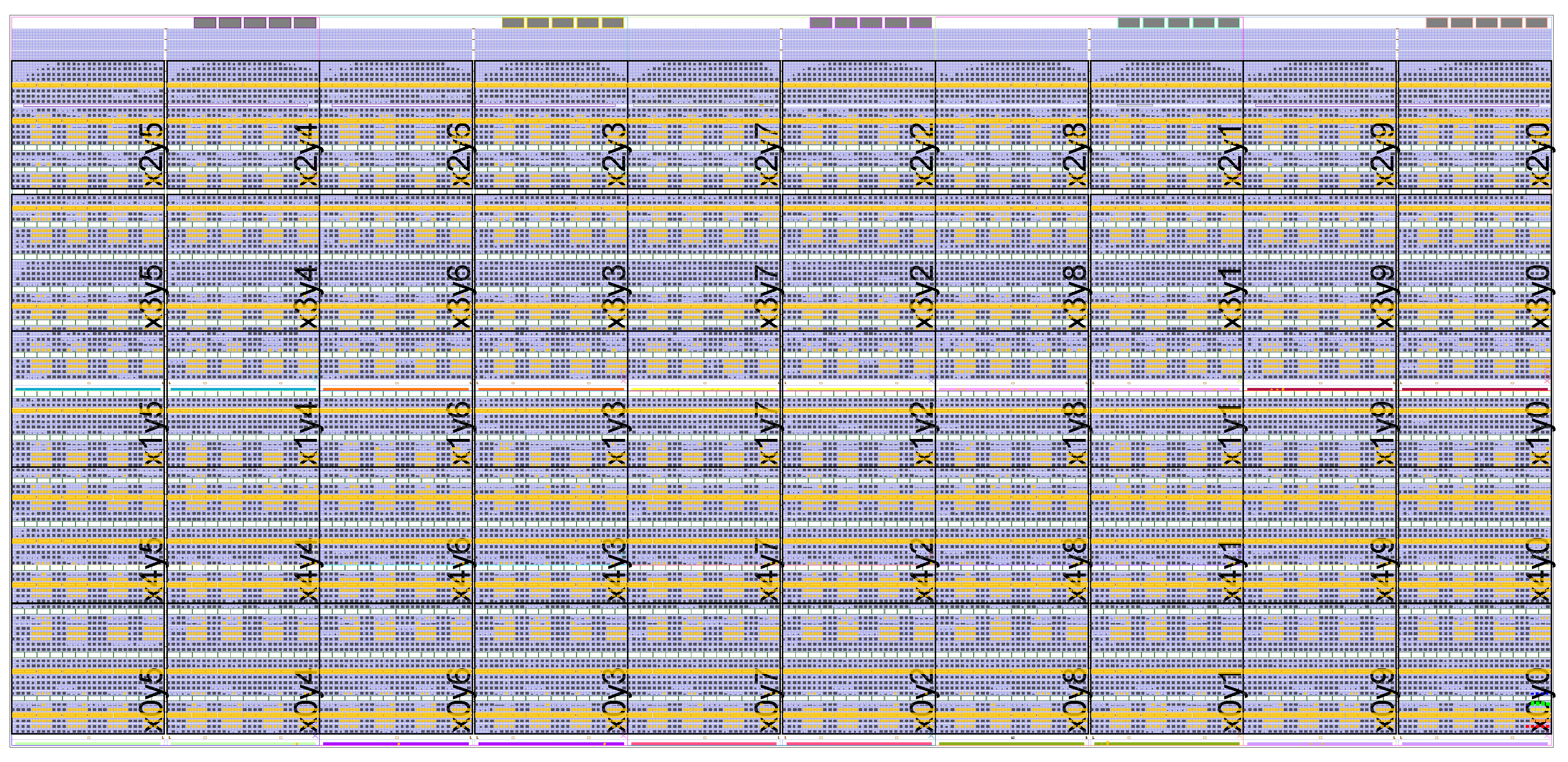
On Dec. 30, 2016, a design with 30 rows by 7 columns of clusters of 8 GRVI RISC-V cores + 128 KB CRAM (cluster RAM) + a 300-bit Hoplite NOC router — a total of 1680 cores and 26 MB of SRAM — booted up and tested successfully, running a message passing matrix multiply workload on all 1680 cores, in a XCVU9P-FLGA2104-2L-E-ES1 device in a Xilinx VCU118 evaluation kit.
This 1680 core GRVI Phalanx is the first operational kilocore RISC-V, the first kilocore 32b RISC in an FPGA, and the most 32b RISC cores on a chip in any technology.

1 core, 32 cores, 1680 cores — RISC-V scales up! A 1-core Si-Five HiFive-1, a 2x2x8=32-core GRVI Phalanx in a Digilent Arty / XC7A35T, and a 30x7x8=1680-core GRVI Phalanx in a Xilinx VCU118 / XCVU9P.
Here is the basic cluster tile architecture redesigned for UltraScale+ and its new 288 Kb UltraRAM jumbo-SRAM blocks. The present design includes 210 instances of this tile.
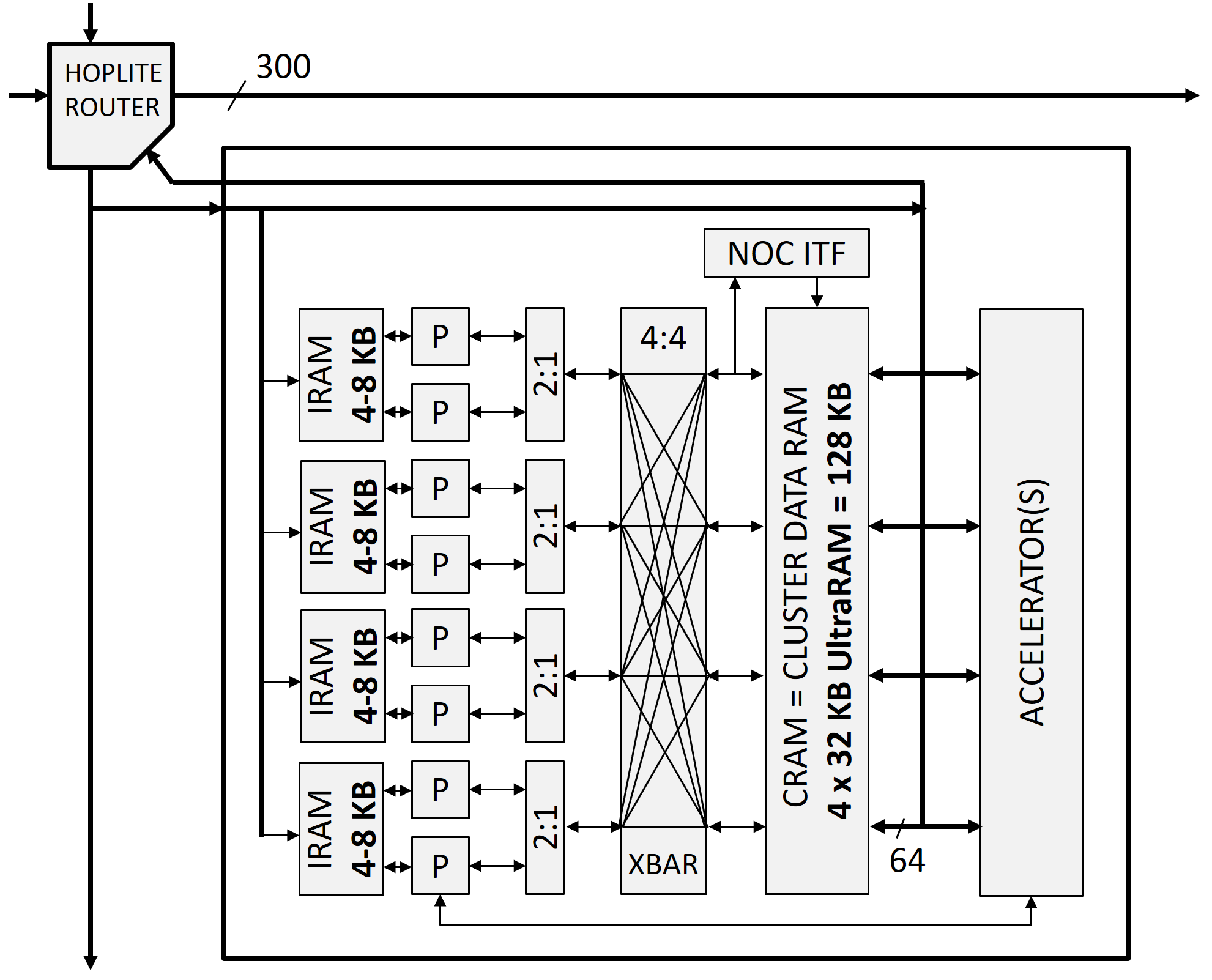
A GRVI cluster tile with 8 GRVI RISC-V cores, 128 KB multiported bank interleaved shared cluster RAM, optional accelerators (here, none), message passing NOC interface, and a 300-bit wide Hoplite NOC router.

An example 1680 GRVI system implemented in a Xilinx Virtex UltraScale+ VU9P. This GRVI Phalanx comprises NX=7 x NY=30 = 210 clusters, each cluster with 8 GRVI cores and a 8-ported 128 KB cluster shared memory. The clusters are interconnected on a Hoplite NOC, with the Hoplite routers configured with 290b data payloads (including 32b address and 256b data), achieving a bandwidth of about 70 Gb/s/link and a NOC bisection bandwidth of 900 Gb/s. Each cluster can send or receive 32 B per cycle into the NOC. The GRVI Phalanx architecture anticipates a variety of configurable accelerators coupled to the processors, the cluster shared RAM, or the NOC.
An extended abstract with additional detail on this work has been submitted to, and hopefully will be presented at, the OLAF’17 workshop at FPGA’17.