
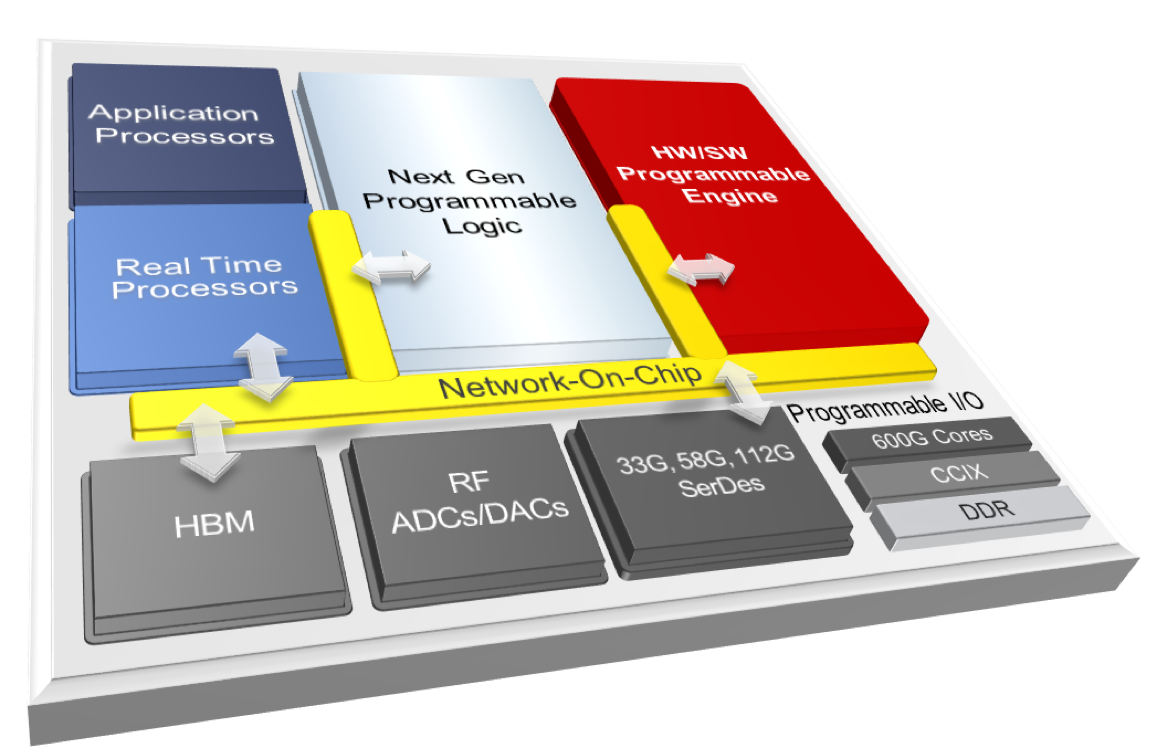
Xilinx Everest block diagram
Everest: A New Adaptive Compute Acceleration Stack
Start with this Xilinx presentation from Victor Peng, Xilinx CEO: Xilinx Vision and Strategy for the Adapatable World. (Dear Xilinx: please share a recording of this presentation.)
Blog and press roundup:
- Matt Hurd, Meanderful blog: Project Everest – Adaptive Compute Acceleration Platform
- Ian Cutress, Anandtech: Xilinx Announces Project Everest: The 7nm FPGA SoC Hybrid
- Dean Takahashi, VentureBeat: Xilinx spent $1 billion over 4 years to make adaptable computing chip
- Jeffrey Burt, The Next Platform: FPGA Maker Xilinx Says the Future of Computing is ACAP
- Dylan McGrath: EE Times: New Xilinx CEO Touts ‘Adaptive Computing’
- Natalie Gagliordi, ZDNet: Xilinx debuts software programmable chip design in data center push
- James Morra, Electronic Design: Xilinx Adapts to an Adaptive Future of Computing
- Chris Mellor, The Register: Xilinx to bust ACAP in the dome of data centres all over with uber FPGA
- Julien Happich, eeNews Europe: Xilinx promises revolutionary architecture at 7nm
- Steven Shankland, CNET: Xilinx’s flexible computer chips could rewire an AI near you
My take: Everest is bold bet on Xilinx’s “data center first” strategy. I see Everest as Xilinx’s response to the present situation that its FPGAs beat GPUs on energy efficiency and integrated data center networking, but not raw compute, and they significantly trail CPUs and GPUs in developer productivity, adoption, and appeal. Just “more of the same” FPGA device scaling and integration was never going to change that.
I think the key ideas and challenges for Everest are to:
- add or harden the compute resources for which GPUs have a competitive edge today (software programmable “engines”, interconnect, memory system);
- keep it scaling up throughout the 2020s;
- make it all much easier for software developers to use and to love.
If Xilinx succeeds, it stands to win share from rival computing platforms, enable and grow new markets, and capture value beyond mere device sales. It is thrilling to see the bantamweight Xilinx innovating furiously versus the Intel+Altera behemoth, with its potential advantages of scale and of platform and tools integration.
(Back in the heyday of Microsoft’s Parallel Computing Platform, circa 2008, our mission was “to deliver lovable parallel programming models and infrastructure” — that is, “to provide models, languages, tools, libraries, and frameworks that make it easier for mainstream software developers to successfully develop and ship software that scales up on new parallel hardware”. Here Xilinx’s job one is similarly to make their top-to-bottom technology stack lovable to cloud services developers and cloud operators — competitive with/superior to CPUs, MICs, GPUs, and ASICs, on criteria including throughput, efficiency, cost, developer appeal, agility, and time to market.)
With VU37P HBM2-in-package memory and its CCIX interface, Xilinx catches GPUs/APUs in DRAM-tier memory bandwidth and coherent shared memory host integration. But that doesn’t address FPGAs’ raw compute and productivity shortcomings. SDAccel, i.e. OpenCL-based software defined accelerator hardware, is a leap forward, but with each mind-numbing multi-hour-build design iteration it loses the hearts and minds of high performance software developers.
Software-first, software-mostly, massively parallel compute and accelerator FPGA overlays, such as GRVI Phalanx (and its Hoplite NoC) provide minimum developer table-stakes: the rapid turnaround and NDRange data parallel programming model of recompile-and-go GPUs. But even obsessively-FPGA-optimized soft processor array overlays, with custom function units and accelerator cores, often cannot compete with full custom (e.g. GPU streaming multiprocessor) processing elements for cost, throughput, or energy efficiency. The FPGA cost, of bit-granularity programmable gates and wires, is too high when you are are instantiating e.g. 1680 processors.
So to compete and win in data center acceleration in the next decade, Xilinx has no alternative but to complement its leadership in programmable logic + SRAM + DSP + SERDES, with massive throughput software programmable “engines” and the requisite scalable interconnect NoC and memory system. (“20x” 20 TOPS INT8 ML inference is indeed “massive”.)
The concept of a bit-oriented FPGA hybridized with word oriented, massive throughput software programmability is not new. The many thousands of Xilinx DSP blocks (*), tailored for efficient FIR filters and such, were always tantalizingly close to (but yet so far from) software programmability. Projects like iDEA show the promise and the disappointment of running C code on DSP blocks + BRAMs. ASICs such as the Ambric Am2045 MPPA, the Adapteva Epiphany, the Kalray MPPA, Picohip’s picoArray, and many other MPPA, CGRA, RAW, etc. projects, albeit more for embedded systems than data center, were more than competitive with CPUs and GPUs, but ultimately did not disrupt the CPU-GPU-FPGA-ASIC status quo. Why? In part, they lacked synergistic SOC integration with the rest of the heterogeneous ARM-MPSOC-FPGA that e.g. Zynq / Zynq UltraScale+ MPSOC enjoy. In part they did not sufficiently deliver the developer love. In part these technologies were advanced by companies that did not have the requisite breadth or scale or sales channels or deep pockets. I think Project Everett can succeed where they did not.
( (*) You know, for a few gates more, the DSP48 block could have been our generation’s AMD2900 bitslice processor-kit. The poor DSP block just need a register file and a better result forwarding mux network. For want of a “Mick and Brick” we must build our phalanxes out of LUTs better spent on custom accelerators.)
Until the recent emergence of massive data center workloads (data analytics, AI/ML/vision, video) and data center scale FPGA farms (Catapult v2) there was no compelling value proposition to move Xilinx or Altera to gamble expensive FPGA die area, power budgets, and huge tools and libraries investments on massive throughput programmability. But now Xilinx sees “data center first” as their business imperative for the 2020s.
It’s a Heterogeneous, Specialized, Networked, Adaptive Computing World
While we await answers to questions such as “so what are these HW-SW programmable engines?”, “how do you program them?”, “will my current workload run on them?”, “what is the memory system?”, “how do software and hardware elements compose?”, and “so what is the difference between UltraScale programmable logic and ‘next generation’ programmable logic?”, it is clear that “Xilinx FPGAs” of the future will complement programmable logic with diverse programmable engines and application processors.
And what is the “right” mix of hardened processing elements and programmable logic? It depends. In the wake of its Zynq MPSOC-FPGA offerings, Xilinx is set to combine many types of computational resources in one ultra heterogeneous device, combining (surely ARM) app processors and real-time processors with the new programmable engines and programmable logic.
Note Xilinx’s mastery of multi-die “2.5D” packaging enables a flexible product mix of processing elements and programmable logic, composed on a hard network-on-a-chip (NoC) which presumably will span dies.
As we work to advance FPGA-efficient soft NoCs like Hoplite, we feel that hard NoCs complement, but not replace soft NoCs. For years to come, the installed base (including UltraScale+ VU9P, VU2xP, VU37P, Arria-10, Stratix-10, etc.) will require soft NoCs. Especially VU37P. And in a hard NoC device, there are even more resources for the fabric resources to reach and connect to. Much more many-to-many communication. Metcalfe’s Law in the small.
A Leap Ahead on Performance and Efficiency
Xilinx heralds several Everest breakthroughs including an astounding 20x boost on AI compute and 4x on 5G communications. Some of this scale up certainly comes the transition from TSMC 16 nm to 7 nm technology nodes, but this time much of the improvement must come from architecture, and in particular those new, mysterious programmable hardware engines.
In footnotes, Xilinx states the Everest 20x speedup is on an ML image recognition inference workload, versus a VU9P with 7000 DSPs at max performance. At max performance, on INT8-optimized ML inference, the latter can approach 20 TOPS, at 200+ GOPS/W. Does Everest achieve 400 TOPS? At 4 TOPS/W?? We’ll see.
Looking Ahead to 2020, and the Software Stack Challenge
On the hardware front, Xilinx new device products engineering is executing well, quickly mastering new technology nodes and packaging innovations to ship new devices and tools. (For example, I found zero device or tools bugs in porting a dense, complex 1680-core GRVI Phalanx to VU9P ES1 silicon in 12/2016 — it just worked.) This bodes well for a rapid and successful development and roll out of these new 7nm Everest devices.
But the impact and uptake of Everest depends to the greatest extent on the software stack. Xilinx has targeted several vertical domains — AI, video, genomics — with a familiar, successful model of prebuilt high level frameworks, libraries, and tools stacks. Now Xilinx will have to prime the pump for Everest themselves. Xilinx, The Programmable Logic Company The All Programmable Company — can they become a great software and software developer tools company too? Will they have the will and the scale to invest in new languages, compilers, debuggers, profilers, runtimes, libraries, and yet more libraries to compete for developer mindshare at the level of NVIDIA, Intel, or Microsoft?
Xilinx can, must, and will enable software developers in key market segments harness these new programmable engines with turnkey software stacks. Developers will bring TensorFlow, ONNX, etc. models to Everest-enabled frameworks and run them instantly, without ever spinning a bitstream or editing a line of XDC or Verilog.
It follows that Xilinx and its domain partners will be very busy providing to their new customers prebuilt solutions stacks. (Intel too, can, must, and will pursue this strategy.) This also affords Xilinx and its partners an opportunity to accrue IP value up the software stack, selling accelerated software solutions priced at the value proposition they bring to customers, no longer just selling silicon devices at whatever LUTs/$ vs. Intel and others.
My mission is to make it easier to compute with FPGAs. More than ever, that’s Xilinx’s mission too. It’s an exciting time in the FPGA world; once again the sky is the limit.
(For a stale but fun 2013 take on FPGAs in the data center, check out Reconfigurable Computing in the Era of Dark Silicon.)