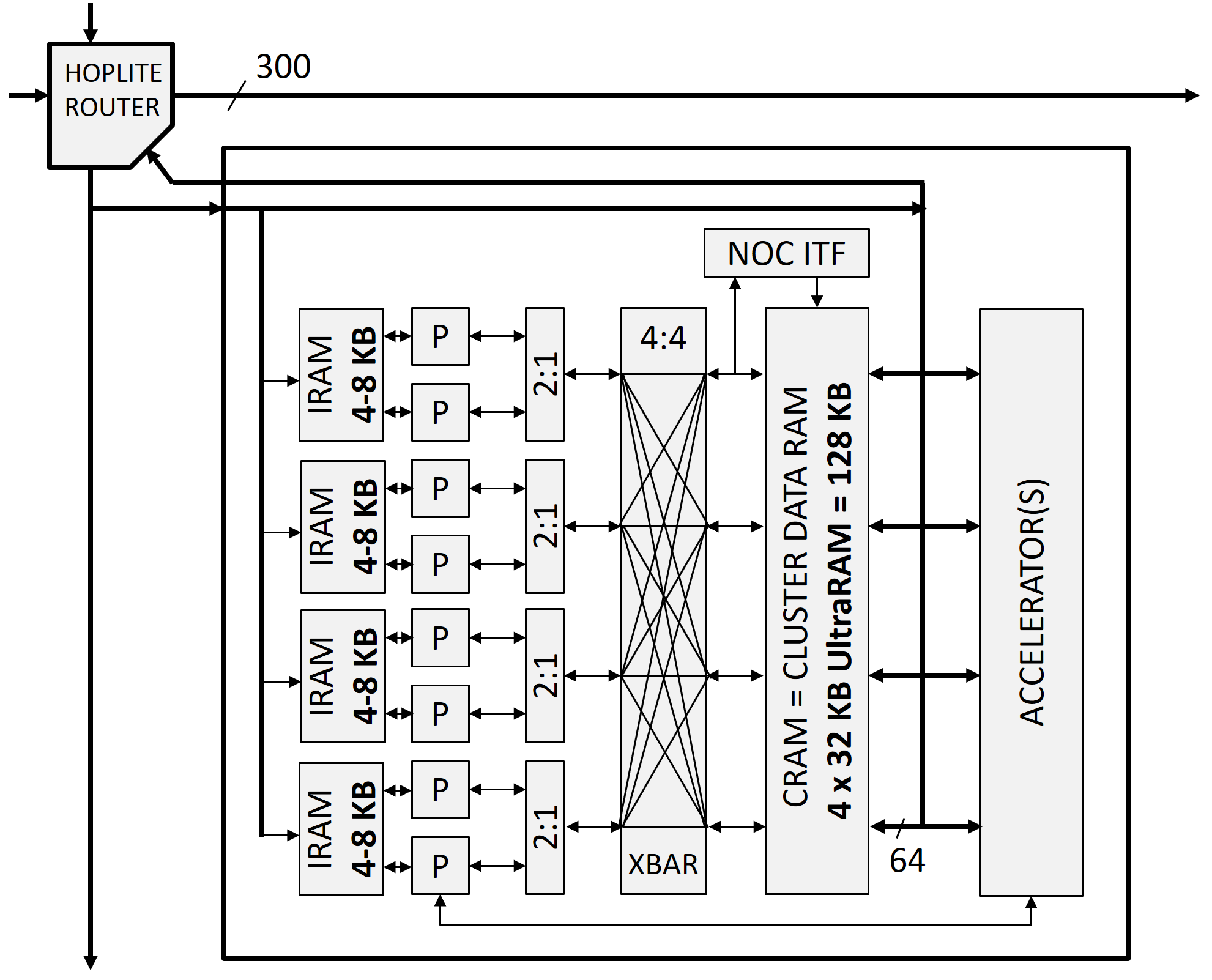
Yesterday at Hot Chips 29 (2017) I presented a poster GRVI Phalanx: A Massively Parallel RISC-V FPGA Accelerator Framework: A 1680-core, 26 MB SRAM Parallel Processor Overlay on Xilinx UltraScale+ VU9P (PDF) and some hardware demos. Extended abstract (PDF).  The poster focuses on the Dec. 2016 1680 core milestone but also describes plans and ideas for programming models and tools, and recent work towards AWS F1 and PYNQ-Z1 general availability, including work on AXI4-MM and AXI4-Stream bridges to the Hoplite NoC fabric, enabling AXI4 DRAM / Phalanx-RDMA interface support for Zynq 7000 (hard DRAM controllers behind the HP[0-3] ports) and AXI4 64b DDR4-2400 MIG DRAM interfaces on KU040 and VU9P.
The poster focuses on the Dec. 2016 1680 core milestone but also describes plans and ideas for programming models and tools, and recent work towards AWS F1 and PYNQ-Z1 general availability, including work on AXI4-MM and AXI4-Stream bridges to the Hoplite NoC fabric, enabling AXI4 DRAM / Phalanx-RDMA interface support for Zynq 7000 (hard DRAM controllers behind the HP[0-3] ports) and AXI4 64b DDR4-2400 MIG DRAM interfaces on KU040 and VU9P.
In the adjacent RISC-V Foundation booth, I set up two demos:
- A 1680-core, 26 MB GRVI Phalanx on VU9P on VCU118, with a 7×30×300b Hoplite NoC and 7×30 clusters of { 8 RISC-V cores + 128 KB }, running a message passing, bulk synchronous integer matrix multiplies demo, and
- An 80-core GRVI Phalanx on 7Z020 on PYNQ-Z1, with a 4×4×300b Hoplite NoC and 10 clusters of { 8 RISC-V cores + 32 KB }, running an AXI4 DRAM/RDMA bridge test of 80×256B×2^28 reads. (Some of the 80 cores’ blue and white subwindows of the console are visible in the photo below.)
This just underscores that I need to invest in better demos.

Demos of GRVI Phalanx on PYNQ-Z1 (80 cores) and VCU118 (1680 cores) at the RISC-V table at Hot Chips 29
This event was a special occasion for me. I’ve attended Hot Chips conferences since the late 1980s. Then, as a software engineer fascinated by computer architecture and following USENET’s comp.arch gang, it was a thrill for me to head to Stanford and meet my heroes, microprocessor architects, and learn more about how their new parts worked, and I’d return with new insights that made me a better software engineer.
Back in the ’80s, only chip design teams had the EDA tools and fabs necessary to build microprocessors. But starting in the ’90s, larger and more capable FPGAs, with increasingly comprehensive tools and infrastructure, enabled anyone to develop FPGA CPUs and now parallel computers. FPGAs democratize access to high performance digital design, and yesterday to bring this full circle, I demonstrated a parallel computer system on a chip integrating the greatest number of 32-bit RISC processors ever. With this kind of work, and with the Microsoft Brainwave announcement, FPGA designers are emphatically not second class, second best to inflexible ASICs. Rather FPGA platforms are coequal and indeed are the vanguard of agile computer architecture.