
GRVI is an FPGA-efficient RISC-V RV32I soft processor core, hand technology mapped and floorplanned for best performance/area as a processing element (PE) in a parallel processor. GRVI implements a 2 or 3 stage single issue pipeline, typically consumes 320 6-LUTS in a Xilinx UltraScale FPGA, and currently runs at 300-375 MHz in a Kintex UltraScale (-2) in a standalone configuration with most favorable placement of local BRAMs.
Phalanx is massively parallel FPGA accelerator framework, designed to reduce the effort and cost of developing and maintaining FPGA accelerators. A Phalanx is a composition of many clusters of soft processors and accelerator cores with extreme bandwidth memory and I/O interfaces on a Hoplite NOC. Across clusters, cores and accelerators communicate by message passing.
Talks and Publications
GRVI Phalanx was introduced on January 5, 2016, at the 3rd RISC-V Workshop at Redwood Shores, CA. Presentation slides and video.
Jan Gray, GRVI Phalanx: A Massively Parallel RISC-V FPGA Accelerator Accelerator, 24th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM 2016), May 2016. Received the FCCM 2016 Best Short Paper Award. [PDF]
Nov. 29, 2017: GRVI Phalanx Update: Plowing the Cloud with Thousands of RISC-V Chickens (slides PDF) (12 min video) at the 7th RISC-V Workshop. This talk for the RISC-V community recaps the purpose, design, and implementation of the GRVI Phalanx Accelerator Kit, recent work, and present work in progress to deliver an SDK for AWS EC2 F1 and PYNQ-Z1, including an OpenCL-like programming model built upon Xilinx SDAccel.
Examples
Here are some example GRVI Phalanx designs:
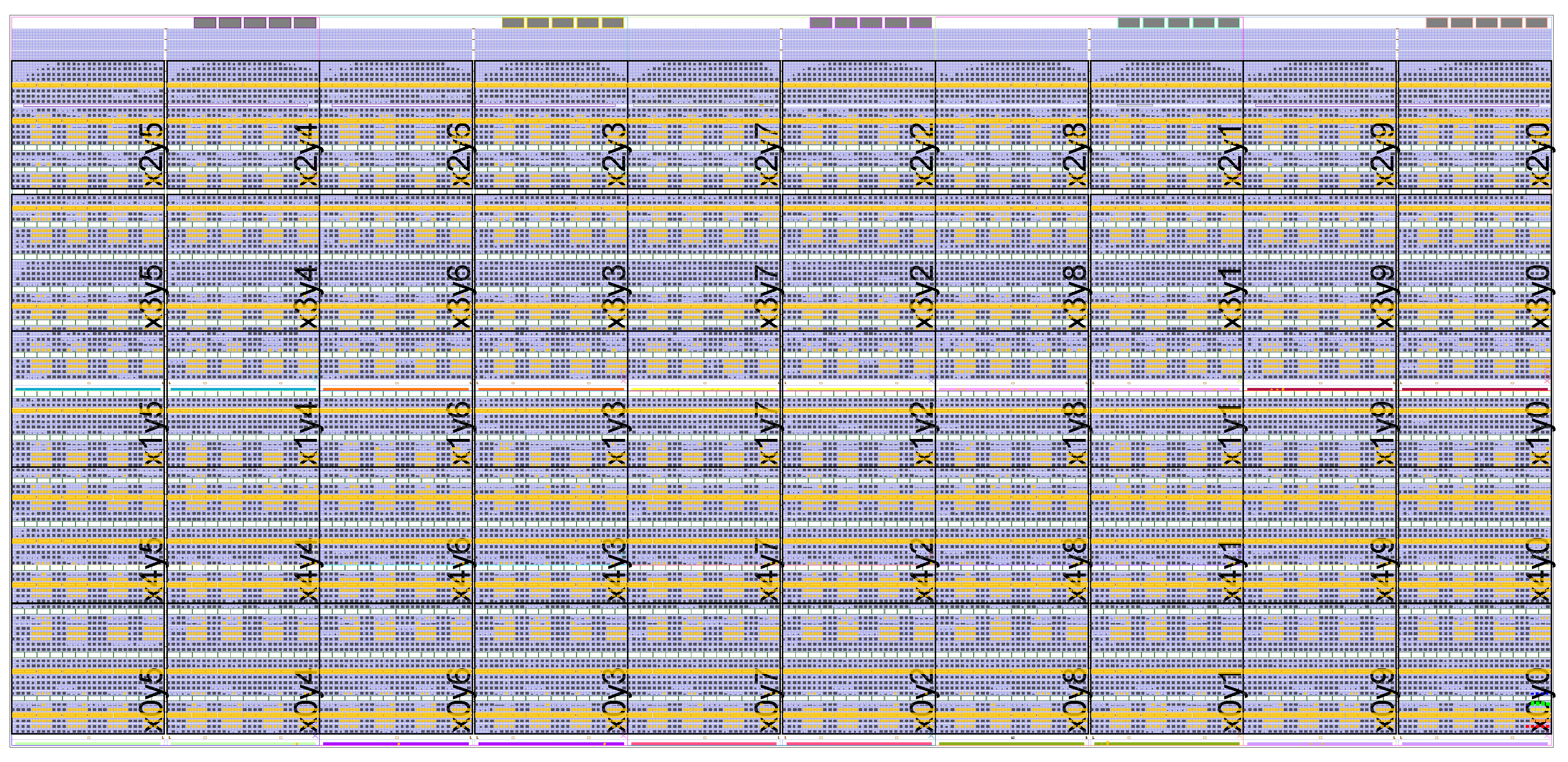
An example 400 GRVI system implemented in a Xilinx Kintex UltraScale KU040. This GRVI Phalanx comprises NX=5 x NY=10 = 50 clusters, each cluster with 8 GRVI cores and a 12-ported 32 KB cluster shared memory. The clusters are interconnected on a Hoplite NOC, with the Hoplite routers configured with 290b data payloads (including 32b address and 256b data), achieving a bandwidth of about 70 Gb/s/link and a NOC bisection bandwidth of 700 Gb/s. Each cluster can send or receive 32 B per cycle into the NOC. The GRVI Phalanx architecture anticipates a variety of configurable accelerators coupled to the processors, the cluster shared RAM, or the NOC.

An example 1680 GRVI system with 26 MB of SRAM, implemented in a Xilinx Virtex UltraScale+ VU9P. This GRVI Phalanx comprises NX=7 x NY=30 = 210 clusters, each cluster with 8 GRVI cores, an 8-ported 128 KB cluster shared memory, and a 300-bit Hoplite NOC router.
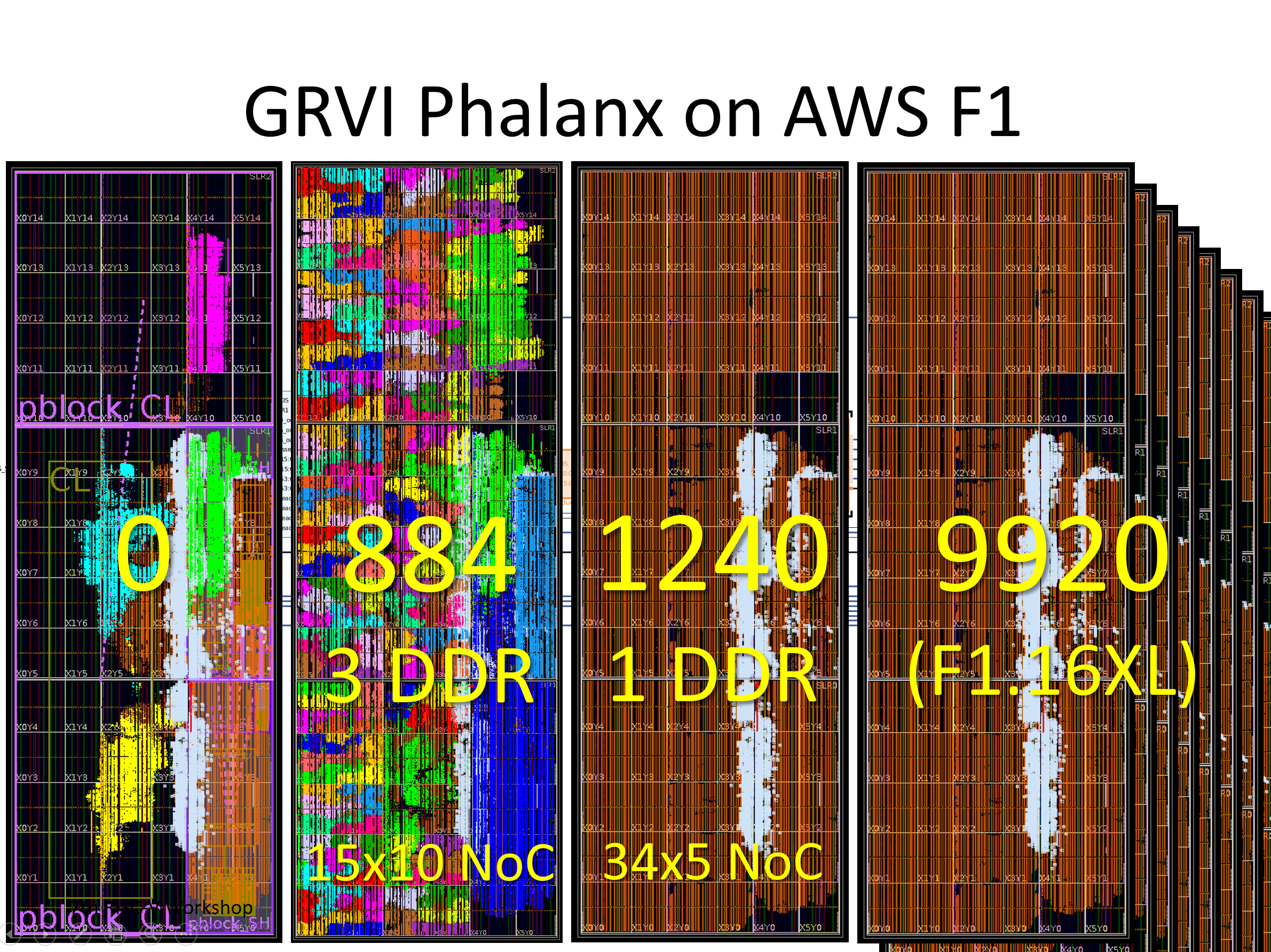
GRVI Phalanx on AWS F1 — die plots of various work-in-progress XCVU9P F1 designs including: 0 cores with 4 DDR4 DRAM channels, 884 cores with 3 channels, 1240 cores with 1 channel, and 9920 cores (8 FPGA slots, on AWS F1.16xlarge).
Other Conference Sightings
An extended abstract and talk on GRVI Phalanx was presented at the 2nd International Workshop on Overlay Architectures (OLAF-2) at FPGA 2016.
GRVI Phalanx was discussed in the short talk Software-First, Software Mostly: Fast Starting with Parallel Programming for Processor Array Overlays at the Arduino-like Fast-Start for FPGAs pre-conference workshop at FCCM 2016. Slides.