GRVI is an FPGA-efficient RISC-V RV32I soft processor core, hand technology mapped and floorplanned for best performance/area as a processing element (PE) in a parallel processor. GRVI implements a 2 or 3 stage single issue pipeline, typically consumes 320 6-LUTS in a Xilinx UltraScale FPGA, and currently runs at 300-375 MHz in a Kintex UltraScale (-2) in a standalone configuration with most favorable placement of local BRAMs.
Phalanx is massively parallel FPGA accelerator framework, designed to reduce the effort and cost of developing and maintaining FPGA accelerators. A Phalanx is a composition of many clusters of soft processors and accelerator cores with extreme bandwidth memory and I/O interfaces on a Hoplite NOC.
GRVI Phalanx was introduced today at the 3rd RISC-V Workshop at Redwood Shores, CA.
A work-in-progress 5x10x8 = 400 processor configuration in a KU040 in a Xilinx KCU105 and a 2x2x8 = 32 processor configuration in a Xilinx Artix-7 35T in an Digilent Arty were demonstrated in the demo/poster session.
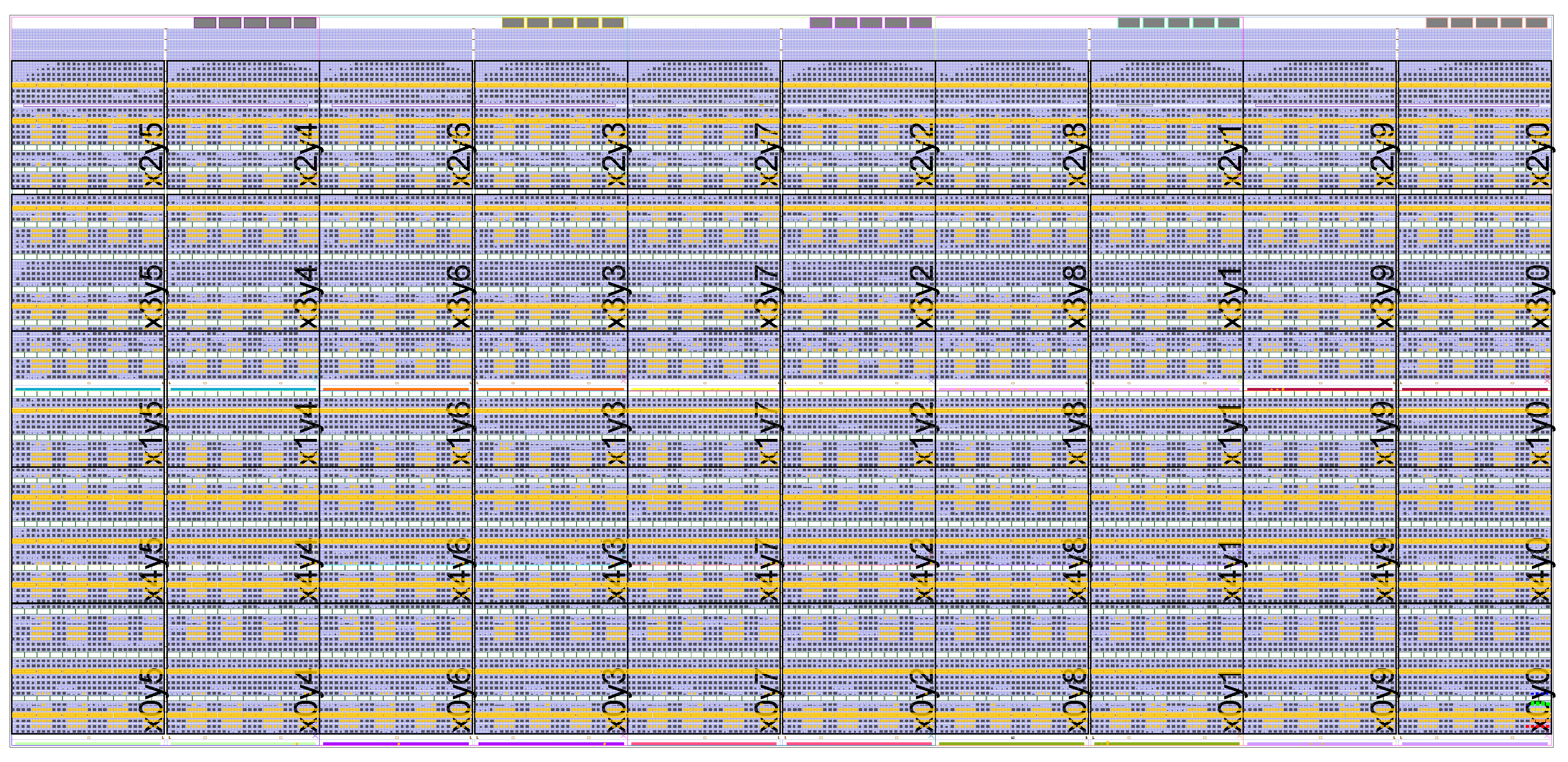
For more information please visit the GRVI Phalanx page.