Welcome to the 10 nm CMOS era! In its first Technology and Manufacturing Day event (press kit, all presentations), Intel unveiled and detailed the highlights of their forthcoming 10 nm process technology node. It’s better than I expected. Intel’s new 10 nm process almost triples the capacity of new integrated circuits, so that the performance and capabilities of our systems can again “leap ahead” and deliver new platforms and experiences. It’s like a three year contract extension. Laissez les bon temps rouler!
The Autumn of Moore’s Law
Computer performance necessarily surfs transistor technology scaling trends. (See The Autumn of Moore’s Law: Scaling up Computing Performance 2011-2020.) For the past 50 years, transistor scaling has been the wind in the sails of the computer industry. Every couple of years transistors per chip double and cost per transistor halves, and this powers disruptive innovations like iPhones, wireless broadband, datacenters with 100 Gbps networking, self-driving cars and self-piloting drones, mixed reality, and deep learning.
These scaling trends have slowed somewhat in the 2010s. We have left the Dennard scaling era. Transistor performance (area times delay) and energy efficiency (gates switched per unit energy) no longer double as feature widths and heights each scale down by a factor of 1/√2 ≈ 0.7. And now each such lithographic feature shrink is taking more than two years.
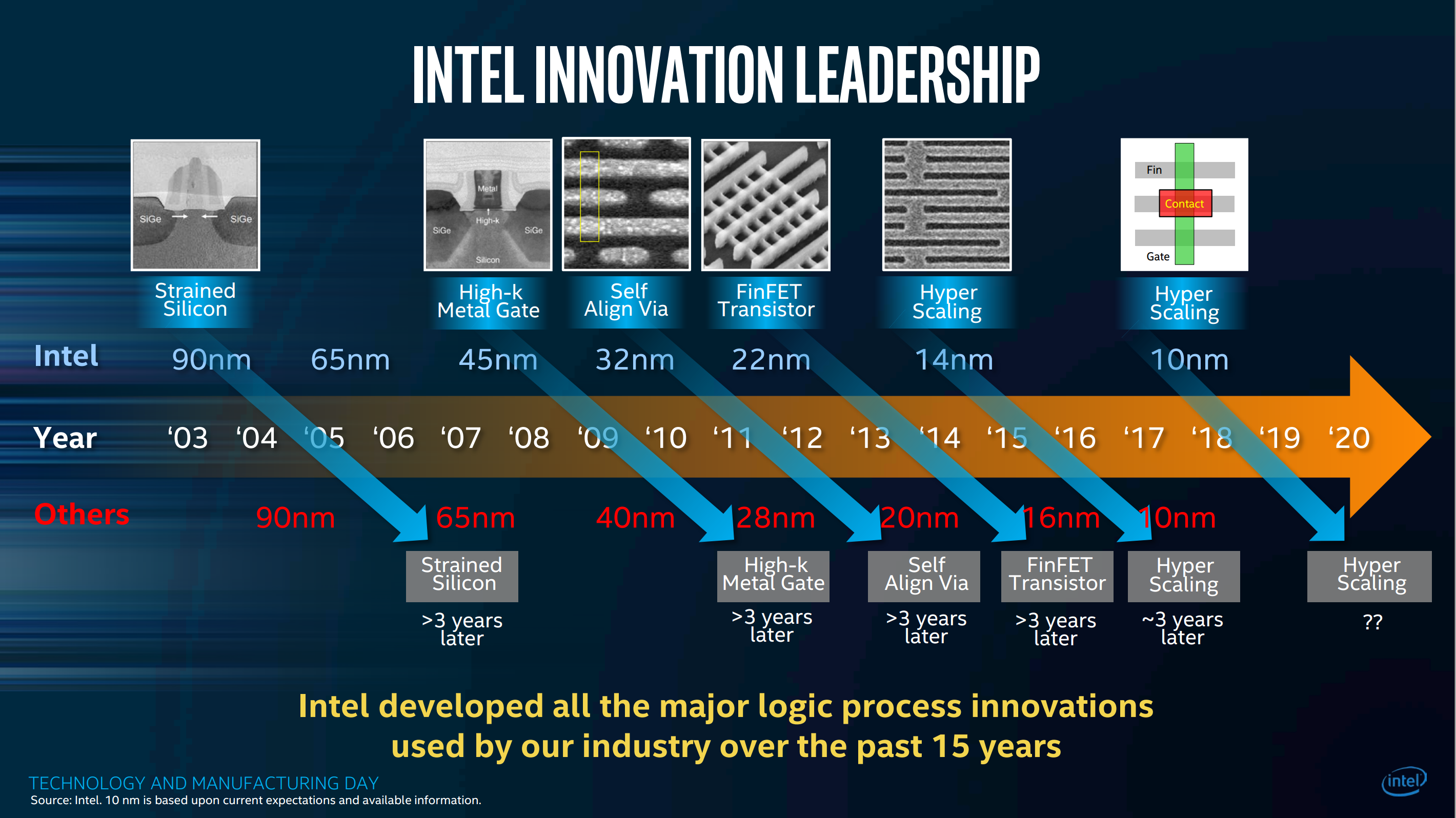
This decade, Intel’s innovations in high volume manufacturing with high-K metal gates, FinFETs and SADP (self-aligned double patterning) lithography have kept Moore’s Law ticking along. But now Intel has been stuck on the 14 nm technology node for at least one year longer than we expected. The familiar yearly tick, tock of process and architecture advances has been a tick, tock, tock, tock. Has Intel manufacturing lost its mojo?
Scaling Down
Emphatically: no. As introduced by EVP Stacy Smith and detailed in Intel Senior Fellow Mark Bohr’s presentation and CVP Kaizad Mistry’s presentation, Intel’s new 10 nm process, announced 32 months after the 14 nm process launch, achieves a remarkable 2.7× transistor density improvement over its predecessor. This is achieved by combining pure lithography scaling with new transistor topology and circuit layout advances that together scale the area of an average logic cell, not at 0.5× but at 0.37×. (This compounds with the impressive 0.37× scaling Intel achieved moving from 22 nm to 14 nm.) Unfortunately SRAM cell scaling at ~0.6× from 14 nm is less dramatic.
Intel 10 nm lithography now requires self-aligned quad patterning (SAQP) at least for 36 nm pitch metal interconnect. Apparently soft x-ray Extreme UV litho is still not ready for prime time. So the challenge is to pattern very narrow rows of lines on the die to lay out FET structures and wires. How can you image such narrow lines using fuzzy 193 nm deep UV laser light? You first pattern the finest lines you can optically using every trick in the book, high numerical aperture immersion, phase shift masks, and computational lithography, then etch/deposit sidewall spacers on the lines that (after more processing steps) become masks, to pattern twice as many lines at half the line pitch. (Multiple patterning (“sidewall image transfer”). I understand that SAQP is SADP and then SADP again. These ultra fine features are achieved only with many extra (expensive) lithographic processing steps.

Beyond lithography, the third generation FinFET transistors themselves are taller (54 nm) and narrower (34 nm pitch), as compared to 42×42 nm in 14 nm, and 34×60 nm in 22 nm; and now the gate contact can be placed atop the gate (“contact over active gate”) that achieves a 10% area savings versus prior nodes’ alongside-the-gate. Unspecified process innovations also enable a new standard cell layout with a shared single dummy gate per cell border which achieves a ~20% area savings. Together with litho scaling these one-time “hyper scaling” improvements boost density scaling from 2.0× to 2.7×. This slide summarizes the improvements.

In the context of an exemplary microprocessor with its mix of logic and regular SRAM, Intel expects overall area scaling at 0.43×, reducing a (complex) processor + cache tile from 17.7 mm2 to 7.6 mm2. This portends a feasible doubling in core counts and cache areas in both client processors and Xeon servers, and a doubling in programmable logic and embedded SRAM resources in future 10 nm FPGAs.
As transistors scale down, the big challenge in spending them to scale up system performance is energy. If you keep doubling transistors per die without doubling gate energy efficiency, eventually you can’t afford to power or cool your integrated circuit, or you have to run it at a lower frequency that it is capable of. This is the dark silicon problem (and for FPGAs, dark fabric). Here too Intel’s 10 nm process makes great strides. Compared to 14 nm, you can get 25% faster switching, or get same performance for 0.55× the power. (I’ll take the latter, thank you.) Furthermore, Intel anticipates follow on nodes 10+ and 10++ with additional performance or power savings. This is welcome news and just significant as the headline 2.7× density scaling.
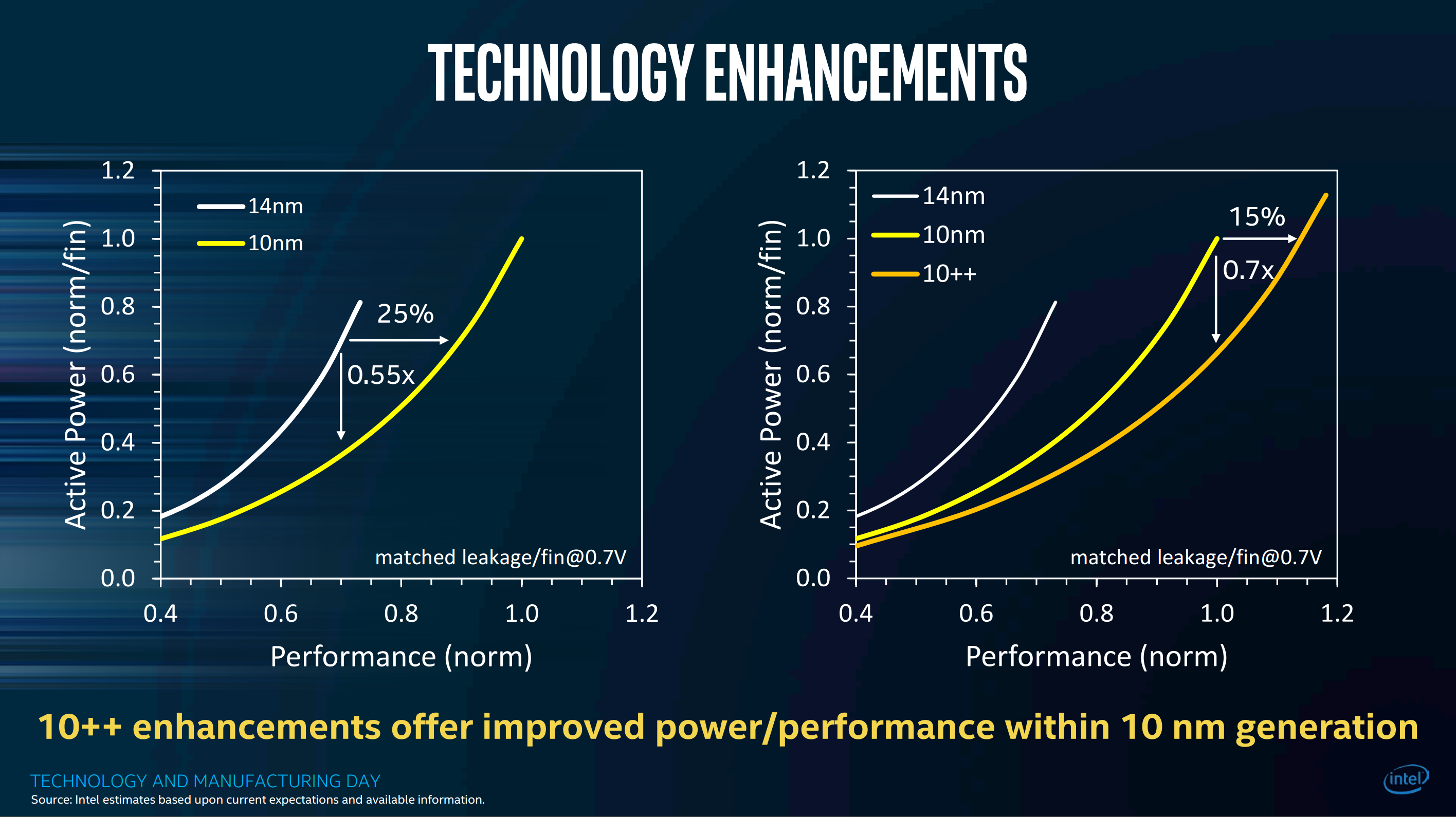
Despite good progress on gate switching energy scaling, the best way forward is still to selectively run serial bottlenecks at higher voltages/frequencies but devote most of the computation to slower, but more energy efficient, parallel compute fabrics. For a perfectly parallel workload, for the same power, you can run the same cores 25% faster, or spend some of your new transistor budget windfall on more processing elements, in pursuit of 81% (1/0.55) greater throughput.
Apples to Apples
Intel underscores their process technology lead versus competing fabs, who are also underway on so-called 10 nm and even 7 nm nodes. Much like FPGA industry’s “marketing system logic cells” (of which there are zero in any FPGA – go open an FPGA device view and see for yourself – none) vs. real delivered 6-LUTs, in process technology specs one-upsmanship there is Intel 10 nm and then there is everybody else’s 10 nm.
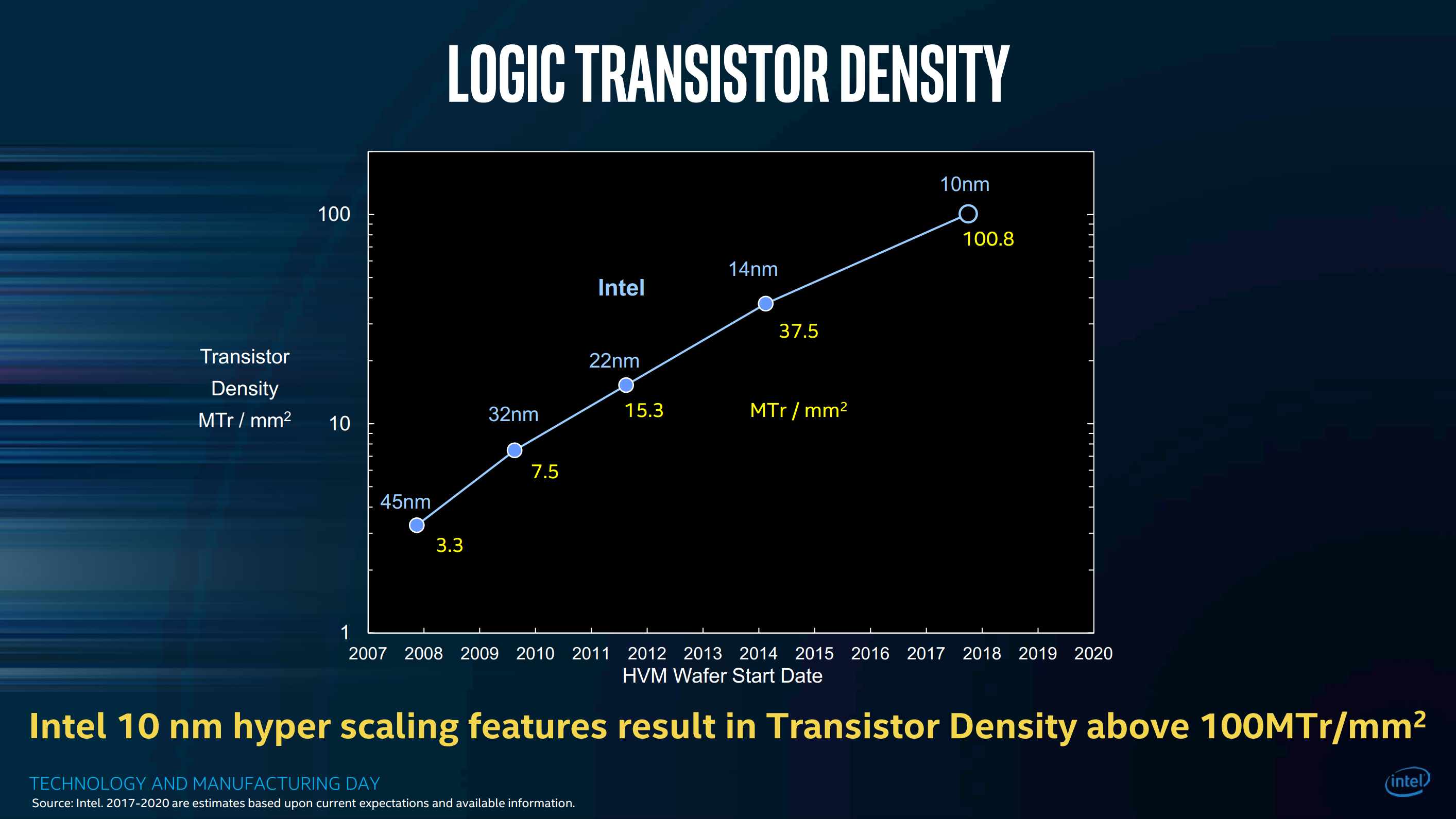
In his editorial Let’s Clear Up the Node Naming Mess, Mark Bohr proposes a benchmark of transistors per square millimeter implementing logic standard cells of 60% NAND2 and 40% SFF (scan flip-flop).

Using this metric, the new 10 nm process achieves 100.8 M transistors per square millimeter. This compares to 37.5 MTr/mm2 in today’s 14 nm and just 7.5 MTr/mm2 in 2010’s 32 nm process. That’s a big leap forward that underscores that Moore’s Law is not dead – not yet.
Agility and Heterogeneous Integration: More than Moore
Slides 37-42 of Bohr’s slides underscore Intel’s EMIB (Embedded Multi-Die Interconnect Bridge) technology, which enables cost effective, high bandwidth, low latency composition of heterogeneous dice in an SiP (system in package). EMIB enables the forthcoming Stratix-10 MX FPGA with HBM2 DRAM die stacks in package, targeting up to 1 TB/s of DRAM bandwidth.
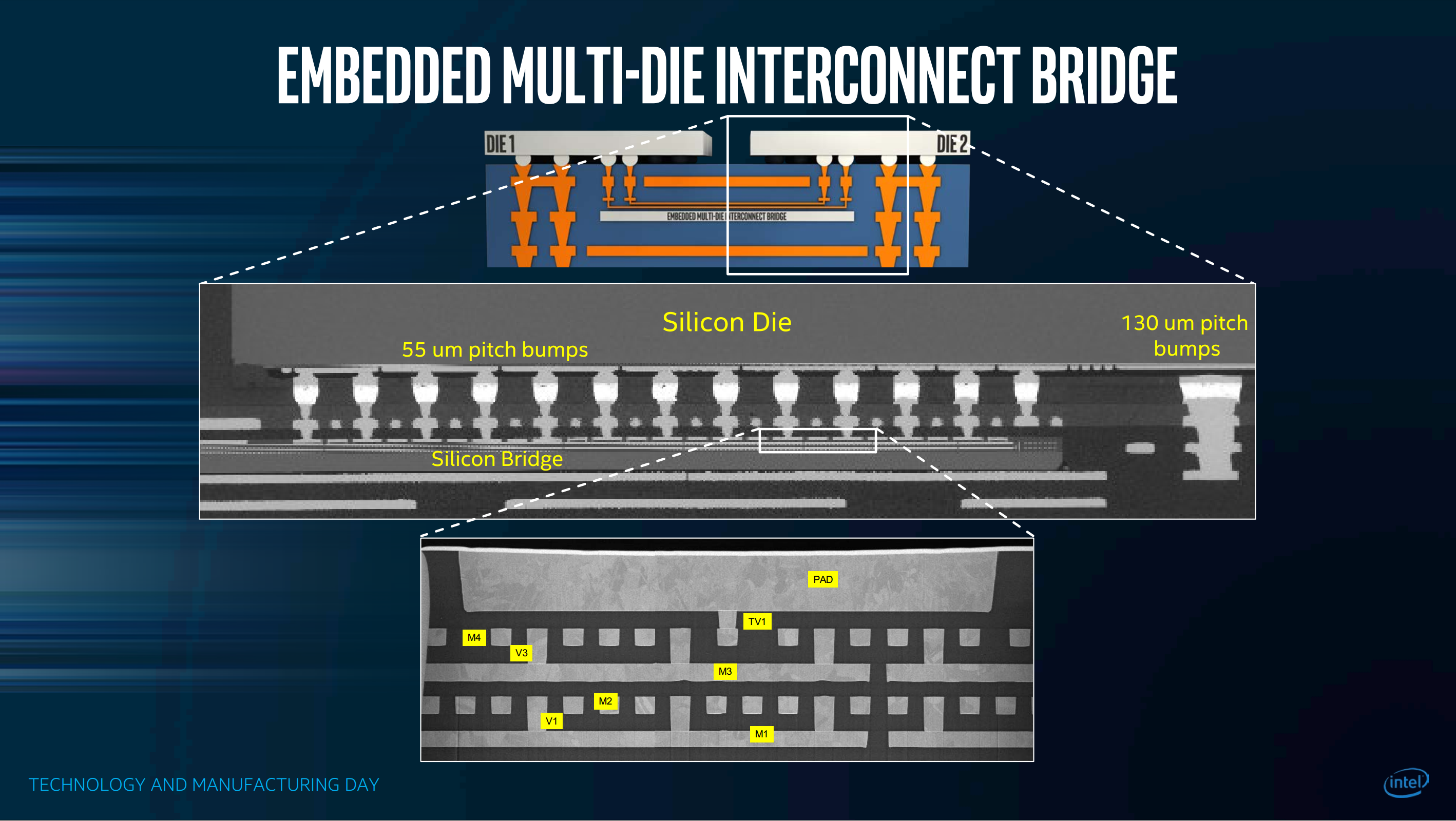
At FPGA 2017, Andrew Putnam of Microsoft Research pointed out that if you already have an EMIB- or SSI-interposer- FPGA, it’s straightforward to build a new FPGA + ASIC (or CPU + ASIC) SiP. Better than a standalone ASIC, a SiP-ASIC doesn’t need PCIe or QPI interface to the FPGA/CPU, doesn’t need high powered 10-28 Gb/s multi-gigabit serial transceivers with clock-data recovery, but rather will employ many hundreds of ~2 GHz low-voltage-swing nets to the FPGA/CPU.
EMIB SiP enables a new kind of agilty that Intel should leverage, both in Xeon-ASIC and Xeon-FPGA-ASIC SiP solutions. For example if a particular binary weight neural network machine learning platform catches on, Intel’s Altera asset enables them to 1) rapidly develop and ship an acceleration solution on a CPU+FPGA SiP (plus a software library version for down level systems); and concurrently develop a BNN-ASIC bare die then 2) assemble and ship a CPU+FPGA+BNN-ASIC SiP, without impact to CPU or FPGA dies, costs, or schedules. Compared to a four year product cycle of new feature pathfinding and value-proposition-proving and architecture review, and so forth — finally achieving production silicon but typically missing first mover advantage — an EMIB-powered ASIC-SiP methodology could cut two years from the process, capturing new business, and providing new work for older fab lines.

What Intel Didn’t Say
The elephant in the room is cost per transistor (CPT) scaling. As per-fab equipment costs rise and per-wafer processing costs rise with multiple patterning, CPT no longer halves as transistors per mm2 doubles. A few years back, NVIDIA complained that transitioning to partner TSMC’s then-new 20 nm planar process could see negligible CPT improvement due to these increased costs. Here though Intel states that their lithographic shrink plus application of one-time hyper scaling techniques (here, contact over active gate and single dummy gate standard cells) overcomes the increasing cost per mm2 to continue the trend of expoentially cheaper transistors — “hyper scaling allows the economics of Moore’s Law to continue”.
I am also curious to whether and what extent (as Intel’s Shekar Borkar discussed 10 years ago) transistor variability across the die and across chips has become a problem that requires (e.g. microarchitectural) attention. Are FinFETs less susceptible to dopant distribution variability than planar transistors?
It is unclear how quickly Intel will be able to ramp up high volume production in this process, what yields they expect in 2018, and how it compares with the competing TSMC 7 nm process that will power the next generation of Xilinx FPGAs.
Also, no sign of silicon photonics in the mainstream.
Into the Grand and Glorious Future
Intel is well positioned with leadership manufacturing, processors, memory, FPGAs, SOC and networking and wireless infrastructure, with its Software and Solutions Group assets, and with new business investments like machine learning and ADAS. Not content to merely fill x86 ISA sockets until oblivion, it is investing and striving to climb up the technology stack and capture more value in new markets.
Next year Intel will crank out several hundred million 10 nm processors, and soon FPGAs and other chips. As an FPGA technologist I am particularly excited about the opportunity to integrate FPGAs into processors — whether monolithic die designs or via EMIB bridges. For forty years increasing transistor budgets have brought integration and democratization of new functions into the platform. By 1989 as transistors doubled not only did Intel pipeline their 386 core but they added a paged MMU and FPU to make the 486. This quickly became a standard platform that software stacks take for granted. Similarly, rather than double the client CPU from 4 cores to 8, or a server from 16 to 32, it may make sense to spend some of the new transistor and power budget to add some FPGA fabric into the system. We’ll see.
My career was built on Intel processors, and my work today still relies upon them. Beyond that, Intel’s remarkable process scaling and manufacturing leadership has led the industry forward. When I use Xilinx Virtex UltraScale+ (16 nm TSMC FinFET) FPGAs, running at 0.72 V at 50 A, I appreciate many of the requisite lithography, process, and circuit technologies involved were invented, nurtured, or perfected at Intel first.
Thank you, Intel. Well done. Hope to see you again in 2020.